| 送交者: An4dy[♂★★★声望勋衔14★★★♂] 于 2024-02-23 10:15 已读 9457 次 | An4dy的个人频道 |
那个和 Midjourney 打得难舍难分,引发了一波买显卡 “ 炼丹 ” “ 炼妹子 ” 风潮的 Stable Diffusion ,又推出船新版本了。
就在昨天晚上, Stability AI 在官网来了一波更新,预告了一波 Stable Diffusion 3 。
根据介绍,新版本在多主题提示、图片质量还有文字渲染能力上都进行了次大升级,模型参数量在 800M-8B 之间,并且延续了他们家一如既往开源的优秀传统。
更重要的是,它和 Sora 一样当起了维新派,摒弃了业内常用的 U-NET 架构,加入 Transformer 和 Diffusion 结合的大家族。
而具体的原理和进步啥的,看不懂没关系,咱们过会儿再聊。
直接先来一波全新的高清无码大图,让大伙们见识下 Stable Diffusion 3 的斤两。
其中文字渲染能力,是这次 Stable Diffusion 3 比较突出的一个亮点。
因为不咋识字儿、不怎么会写字儿,可以说是目前文生图、文生视频的通病了。
就拿世超用 DALL·E 3 生成的 “ Chaping 青花瓷 ” 为例,上面汉字不明所以。。。最重要的 " Chaping " 还拼写错了。。。
基本上可以说自 AI 画图不会画手之后,把文本渲染成图像里准确的文字,也是个难题。
而新版本的 Stable Diffusion ,文化水平就明显高了不少。
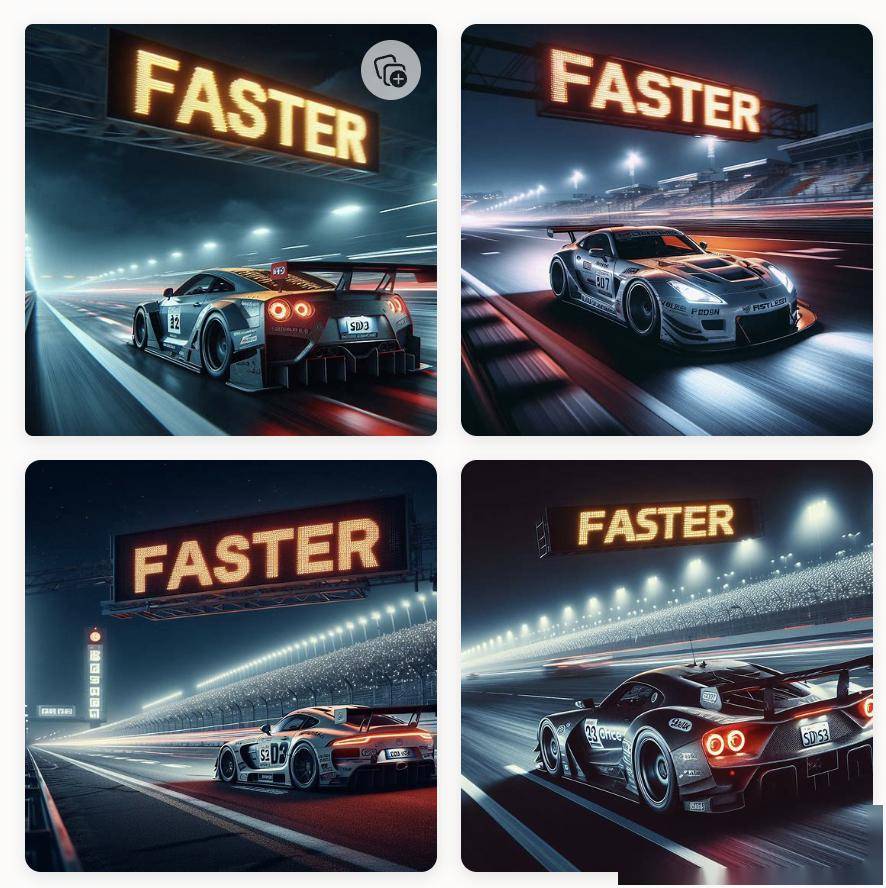
根据官网给出的案例,给它提示词是“ 一辆跑车的夜间照片,侧面写着 ' SD3 ' ,汽车在赛道上高速行驶,巨大的路标上写着 'Faster' 的文字 ” 。
生成的图片不但符合描述,文字的位置也没毛病,字体也很清晰。
但当我们用同样的提示词在 DALL·E 3 生成的时候,文字渲染效果就有些一言难尽了。
Faster 倒是没错,但侧面的 SD3 没有一张图是准确的。
还有这张, Stable Diffusion 3 生成的是这样的。
而 DALL ·E 3 连 incredible 都没拼对。
只不过,现在目前的文字渲染暂时只支持英文,中文还得等上那么一段时间。
再来看这次 Stable Diffusion 3 的另一大更新——多主题提示,大伙儿可以把这个理解成, AI 在生成图片的过程中漏没漏提示词。
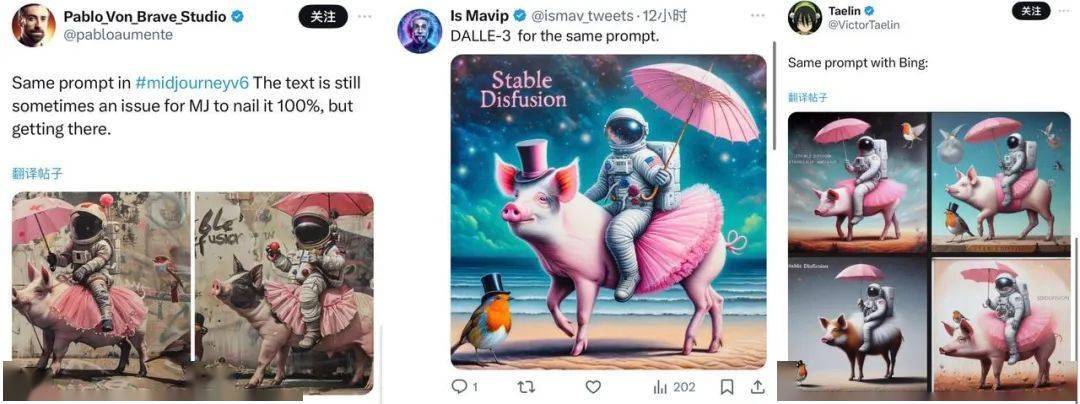
举个例子,这张图的提示词里,大致包括了宇航员、穿着芭蕾舞短裙撑着粉色雨伞的猪、戴着礼帽的知更鸟、还有角落里的 “Stable Diffusion” 几个关键。
咱先不提图片的质量如何,但该生成的东西起码 AI 都没落下。
不过有意思的是,在这条推文下有网友把同样的提示词,分别喂给了 Midjourney 、 DALLE-3 和 Bing 。
看下来, DALLE-3 、 Bing 和 Midjourney 要不就是知更鸟少了帽子,要不就是 “Stable Diffusion” 单词拼写错误,没一个能打的。
最后,是文生图模型最为关键的图像质量。
Stable Diffusion 3 也是人狠话不多, po 了一张这样的图片。
世超第一眼看到的反应:这难道不是照片???
手帕上的纹理还有老虎刺绣,未免有点过于逼真了吧。。。
还有这张苹果,也是能以假乱真的程度。
而之所以 Stable Diffusion 3 这次能有这么大改变,很大可能要归功于一个跟 Sora 同源的架构。
以前的 Stable Diffusion ,一般都是用 U-net 架构 + Diffusion 扩散模型。而 Transformer ,也多是用在像 GPT 类大语言模型上,两种技术各管各的。
而 OpenAI 则觉得 GPT 这把咱用Transformer 打赢了,就不改 banpick 了吧。。。于是就把Transformer 架构和 Diffusion 结合了起来,用在视频上,一顿魔改和大力出奇迹后,就整出了 Sora 。
Stability AI 团队也是英雄所见略同,把Diffusion Transformer ( 简称 Dit 架构 )用在了 Stable Diffusion 3 上。
有意思的是,关于 DiT 架构的论文是 AI 大佬谢赛宁和 William Peebles 一起写的。
这个 William Peebles ,正好是 Sora 团队的负责人之一。
Stability AI 的老板 Emad 也在 X ( 推特 )上表示,这次确实用到了和 sora 类似的技术。
另外,这次 Stable Diffusion 3 还用到了一个 Flow Matching ( 流匹配 )技术。
因为技术原理过于复杂,咱们可以简单理解成,这是一种用来训练扩散模型的方法。
如果把扩散模型比作魔法画笔,那这个流匹配的作用就是升级画笔,让画笔可以更快、更准确地画出你想要的东西。
世超估计也正是因为这个技术, Stable Diffusion 3 的文化水平才暴增的。
总而言之,光从现有的官方效果图和技术公开来看,这次 Stable Diffusion 3 的出现,又把文生图卷到了一个新高度,也证明了 Dit 架构在文生图、文生视频领域确实是个可行的新方向。
反正这么下去,保不齐下一波谁家又会拿出重磅更新。
不过大伙儿也别太焦虑,该吃吃该喝喝,要是有时间学学怎么用 AI 也行。
最后提个醒, Stable Diffusion 3 现在还没正式公测,千万别又让卖课的给骗了。 6park.com